|
 |
|
|||
|
|
|||
|
19. Intellignet
tutoring systems: past, present, and future
|
19.2 PRECURSORS OF ITS 19.2.1 Early, Mechanical SystemsCharles Babbage (early 1800s), is typically credited with being the first to envision a multi-purpose computer. He dreamed of creating an all-purpose machine which he called the "analytic engine." However, because of the technological constraints of the time, he was never able to build his dream, although he did succeed in building a difference engine, an automatic (mechanical) means of calculating logarithm tables. The notion of using "intelligent machines" for teaching purposes can be traced back to 1926 when Pressey built an instructional machine teeming with multiple-choice questions and answers submitted by the teacher(see 2.3.4.2). It delivered questions, then provided immediate feedback to each learner:
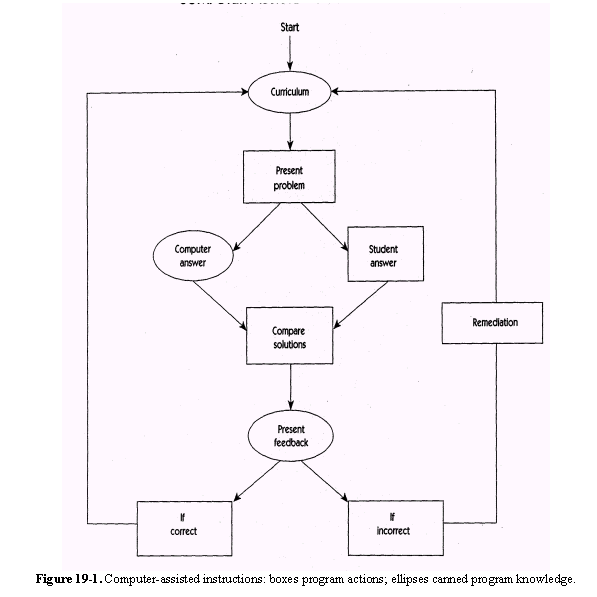
The somewhat astounding way in which the functioning of the apparatus seems to fit in with the so-called 'laws of learning' deserves mention in this connection. The 'law of recency' operates to establish the correct answer in the mind of the subject, since it is always the last answer which is the right one. The 'law of frequency' also cooperates; by chance the right response tends to be made most often, since it is the only response by which the subject can go on to the next question. Further, with the addition of a simple attachment the apparatus will present the subject with a piece of candy or other reward upon his making any given score for which the experimenter may have set the device; that is the 'law of effect' also can be made, automatically(see 2.2.1.3), to aid in the establishing of the right answer (Pressey, 1926, p. 375). While the above system was definitely clever for its time, it could not be construed as intelligent as it was mechanically set with pre-specified questions and answers. So, although it was inflexible, this system did incorporate contemporary learning theories and pedagogical strategies into its design (e.g., giving out candy for correct responses). General-purpose digital computers arose in the mid-1900s, paving the way for truly (artificially) intelligent machines. Basically, these computers consisted of a numerical central processor whose mechanism was electronic, not mechanical, and based on a binary, not decimal, system. They were also characterized by having a built-in ability to make logical decisions, and a built-in device for easy storage and manipulation of data. During this period of computer infancy, Alan Turing (1912-1954, British mathematician and logician) provided a major link between these modern, digital computing systems and thinking. He described a computing system capable of not only "number crunching" but symbolic manipulation as well. He also developed what is now known as the "Turing test," a means of determining a machine's intelligence. The test consists of an individual asking questions, in real-time, of both a human and computer. The interrogator attempts, in any way possible, to figure out which is which via conversations over the communication links. The Turing test has particular relevance to intelligent tutoring systems. The core concept behind the test is whether a reasonable person can distinguish between a computer and a person based solely on their respective responses to whatever questions or statements the interrogator renders. Thus, for a computer to pass the test, it would need to communicate like a human, which is a nontrivial goal. This line of inquiry has challenged and occupied researchers for the past 20+ years, and continues to play a prominent role in the development of ITS (see Merrill, Reiser, Ranney, and Trafton, 1992). Other communication-related research includes devising knowledge structuring and hypertext techniques within ITS to provide answers to the many possible questions that students could pose to the system. So, the success of this ITS enterprise really can be measured in a way that is similar to the Turing test: How well can the ITS communicate? We should point out, however, that the goal of ITS is to communicate its embedded knowledge effectively, not necessarily in an identical manner as human teachers. In fact, some teachers have great difficulty achieving the effective communication goal themselves. Concurrent with the gradual emergence of computers on the scene (circa 1950s), educational psychologists began reporting in the literature that carefully-designed, individualized tutoring produces the best learning for the most people (e.g., Bloom, 1956; Carroll, 1963; Crowder, 1959; Glaser, 1976; Skinner, 1957; see 35.2). Thus, it was quite a natural development to apply computers to the task of individualized teaching. From the 1970s to the present, ITS have been heralded as the most promising approach to delivering such individualized instruction (e.g., Burton & Brown, 1982; Lewis, McArthur, Stasz & Zmuidzinas, 1990; Shute & Regian, 1990; Sleeman & Brown, 1982; Wenger, 1987; Woolf, 1988; Yazdani & Lawler, 1986). We'll now review what led to the development of "intelligent" computerized instruction. 19.2.2 Programmed Instruction and Computer-Assisted InstructionIn the early 1960s, programmed instruction (PI) was educationally fashionable(see 2.3.4, 22.4.1). This kind of pedagogy related to any structured, goal-oriented instruction. According to Bunderson (1970), PI required the program designer to specify input and output in terms of entering skills and terminal behaviors of the learner. In performing a task analysis, the designer determined the sub-problems or component behaviors, as well as their relationships. As learners were led through the problems in the curriculum (lock-step), overt responses were obtained at every step; incorrect responses were immediately corrected, and learners were always informed of their solution accuracy before moving on to some other content area. Most supporters of the PI technology strongly believed that it would enhance learning, particularly for low aptitude individuals. However, evidence supporting this belief was underwhelming (see Cronbach & Snow, 1981). In general, PI refers to any instructional methodology that utilizes a systematic approach to problem decomposition and teaching (e.g., Briggs, Campeau, Gagné, & May, 1967; Gagné, 1965;see 2.3.4, 22.4.1). That PI results in a computer program, known as computer-assisted instruction (CAI or computer-based training, CBT). Some similarities between PI and CAI are that both have well-defined curricula and branching routines (intrinsic branching for PI, conditional branching for CAI). A major distinction between the two is that CAI is administered on a computer.(see 12.1) Computer-assisted instruction also evolved from Skinnerian stimulus-response psychology, "...the student's response serves primarily as a means of determining whether the communication process has been effective and at the same time allows appropriate corrective action to be taken" (Crowder, 1959). In other words, at every point in the curriculum, the computer program evaluates whether the student's answer is right or wrong and then moves the student to the proper path. Built-in remediation loops tutor students who are attempting to answer a question incorrectly. If learners answer correctly, they are moved ahead in the curriculum. Figure 19-1 illustrates a typical flow of events in CAI. The teacher constructs all branching in the program, ahead of time. The normal CAI procedure presents some material to be learned, followed by a problem to be solved that represents a subset of the curriculum. Problem solution tests the learner's acquisition of the knowledge or skill being instructed at that time. The student's answer is compared to the correct answer, then the computer gives appropriate feedback. If the answer is correct, a new problem is selected and presented, but if the student answers incorrectly, remediation is invoked that reviews the earlier material, presents simpler problems that graduate to the depth of the original material, and so forth. Remediation usually requires some attempt to find the source of the error and to treat it specially. As can be seen in Figure 19-1, there are several places where this simple model may be expanded to create more flexibility and, hence, render it adaptive to individual learners. For instance, various mastery criteria can be imposed, where subjects have to answer a certain proportion of items correctly before moving on. Failure to reach criterion would force the student back into remediation mode (see "If Incorrect" branch) where a different problem is presented, rather than the problem that caused the error. COMPUTER-ASSISTED INSTRUCTIONS
19.2.3 Intelligent Computer-Assisted InstructionTo distinguish between simple versus more adaptive CAI (i.e., "intelligent" computer-assisted instruction, ICAI), Wenger (1987) pointed out that actually there is no explicit demarcation between the two. Instead, there's a continuum, from linear CAI, to more complex branching CAI, to elementary ICAI, to autonomous (or stand-alone) ICAI. This continuum is often misconstrued as representing a worse-to-better progression. Yet, for some learning situations and for some curricula, using fancy programming techniques may be like using a shotgun to kill a fly. If a drill-and-practice environment is all that is required to attain a particular instructional goal, then that's what should be used. Suppose you wanted to build a computerized instructional system to help second graders learn double-digit addition. If student A answered the following two problems as: 22 + 39 = 61, and 46 + 37 = 83, you'd surmise (with a fair amount of confidence) that A understood, and could successfully apply, the "carrying procedure." But consider some other responses. Student B answers the same problems with 51 and 73, student C answers with 161 and 203, and student D answers with 61 and 85. Simple CAI systems may be incapable of differentiating these incorrect solutions, and remediation would require all three students to re-do the specific unit of instruction. But a big problem with this approach is that typically, there is little difference between the remedial and original instruction. That means that a student who didn't get it right the first time, may not get it right the next time if the same instruction and similar problems are used. A more sensitive (or intelligent) response by the system would be to diagnose/classify B's answer as a failure to carry a one to the tens column, C's answer as the incorrect adding of the ones column result (11 and 13) to the tens column, and D's as a probable computational error in the second problem (mistakenly adding 6 + 7 = 15 instead of 13). An intelligent system would remediate by specifically addressing each of the three qualitatively different errors. 19.2.3.1 Artificial Intelligence and Cognitive Psychology. How can a computer system be programmed to perform intelligently? This question drives the empirical and engineering research in a field called artificial intelligence (AI). The simplest definition is that, "Artificial intelligence is the study of mental faculties through the use of computational models." (Charniak & McDermott, 1985, p. 6). One of the main objectives of AI is to design and development of computer systems that can solve the same kinds of activities that we deem intelligent (e.g., solving a math problem like the one illustrated above, understanding natural language, programming a computer to perform some function(s), maneuvering an aircraft through obstacles, planning a wedding reception, and so forth; see 22.4.4). There are far too many AI applications to delineate in this chapter. For our purposes, AI techniques relevant to ITS include those dealing with the efficient representation, storage, and retrieval of knowledge (i.e., a large collection of facts and skills--correct and buggy versions), as well as the effective communication of that information. In addition, AI techniques can include inductive and deductive reasoning processes that allow a system to access its own database to derive novel (i.e., not programmed) answers to learners' queries. Cognitive psychology also provides part of the answer to the question of how to get a computer to behave intelligently by examining issues related to the representation and organization of knowledge types in human memory. Research in this area provides detailed structural specifications for implementation in intelligent computer programs. Cognitive psychology also addresses the nature of errors, a critical feature in the design of intelligent systems to assist learners during the learning process(see 12.2.3, 32.5.3). 19.2.3.2 The Nature of Errors. The idea that students and trainees make mistakes that have to be corrected is fundamental to teaching and learning. Something so fundamental ought to be strongly resistant to change, so it is really quite surprising how the idea of a mistake or error has undergone radical change over the past two decades of ITS development. The traditional view of errors encompassed many kinds: from inexplicable accidents, to deliberate inaccuracies; but the most widely held view was that remedial errors stemmed from inaccurate or insufficient knowledge. Remediation then corrected the mistake by providing the correct knowledge or overriding the inaccuracy. The first major shift that occurred in this view began with the development of a theoretical position that errors arose because of complex organizations in knowledge structures that were not wrong, in the traditional sense, but represented the best a student could have at that stage of cognitive development. These developmentally appropriate knowledge structures were called misconceptions, and they were soon analyzed in a broad range of sciences (e.g., Aristotelian versus Newtonian physics, studies of heat and temperature) and practical training environments (automobile repair, radar maintenance). This view of error was explicated in great detail in a series of analyses and experiments by Barbara White and John Frederiksen (1987) in their QUEST system for analyzing levels of understanding of electrical functioning into graduated mental models. Their analyses were actually implemented as qualitative models of the electrical activity in automobile ignition circuits. Simple models, or models that occur developmentally early in the growth of knowledge, were not only incomplete, they were wrong or inconsistent in basic ways. They could not easily be transformed into more complete models. Yet, the simple models effectively captured the knowledge of novices as they moved on the road to expertise, so it is not clear if these models could have been improved at that stage of development. Thus, it appeared that error or inconsistency was necessary in the growth of knowledge. As they demonstrated, it took a great deal of effort to conduct error analysis with sufficient scope and detail to be able to arrive at such complete models. It is perhaps for this reason that no other example comes close to duplicating their feat. Yet, the intellectual implications of graduated mental models as the basis for misconceptions and error is stunningly apparent for whoever next decides to pick up the challenge and analyze knowledge structures into such progressive systems. An alternate conception of error that has developed contemporaneously with the misconception literature, is that of a buggy algorithm. Work in this area began with Burton and Brown's seminal simulation--How The West Was Won--where certain strategic and algorithmic bugs were identified in student play. A specific program was written, DEBUGGY, that attempted to identify and remediate these bugs (Brown & Burton, 1978; Burton, 1982). Unlike the work on misconceptions and graduated mental models, bugs were simpler deconstructions in smaller semantic networks of skills. This analysis of errors has had a productive life of its own in the work of Soloway (catalogs of bugs, Johnson & Soloway, 1984), Sleeman (mal-rules, Sleeman, 1987), and VanLehn (impasses, VanLehn, 1990). It continues strongly in the model-tracing technology of John Anderson's various tutors (e.g., Anderson, 1993) where bug catalogs or lists of errors are embedded in specific production-system rules that manage all interactions between the student and tutor. Anderson has proclaimed a much broader view to encompass not only errors, but all cognitive skills. His position is, simply stated, that cognitive skills are realized by production rules. Not only errors, but all skills, are decomposable into unitary rules that fit into a grand cognitive architecture dominated by production rules. VanLehn's work on impasses extends this buggy conception of errors by analyzing the ways these errors are generated (VanLehn, 1990). Oversimplifying his analysis somewhat, VanLehn's framework can be described by saying that bugs are the result of unsuccessful attempts to extend existing rules to apply to novel situations (repairs). These repairs can be modeled and predicted by impasse theory to predict students bugs and problem solving. Usually the repairs are simple actions, like removing an action step in the production rules, substituting an operator, or deleting a variable. The final view of errors that has evolved along with ITS sees the error as a result of insufficient support given to the student. When a student learns a new skill or body of knowledge, it is through the support of teachers, students, or other parts of the environment. This environment acts as a general scaffolding to strengthen the students first new skills or knowledge structures (Palincsar and Brown, 1984). It also provides the context that makes the skills or knowledge meaningful. Some of this scaffolding lies literally in the minds of the other students or teachers, or more precisely, between the minds of everyone. As a kind of social group think, the ideas and scaffolding are part of the total situation (Brown, Collins, & Duguid, 1989) and so it has been called situated cognition. If the environment is literally part of the skills and knowledge, then changing it abruptly can actually change student thinking and lead directly to errors. This fascinating research related to different kinds of errors owes its existence directly to the practical and theoretical developments that ITS have spawned. All have real import for the design of instruction, but at the moment, they are still very distant from each other and show no real signs of converging into a common theoretical framework. 19.2.3.3. Summary. Branching is a fundamental aspect of PI, CAI, and ICAI. It recognizes the fact that knowledge is interrelated in many complex ways, and there may be multiple good paths through the curriculum. AI programming techniques empower the computer to manifest intelligence by going beyond what's explicitly programmed, understanding student inputs, and generating rational responses based on reasoning from the inputs and the system's own database. In the example just provided, prior to teaching double-digit addition, the system could first ascertain if the learner was skilled (to the point of automaticity) with single-digit addition, drilling the learner across a variety of problems, noting accuracy and latency for each solution. Subsequently, it may be effective to introduce (a) double-digit addition without the carrying procedure (23 + 41), (b) single- to double-digit addition (5 + 32), or (c) single-digit addition to 10 (7 + 10). Each of these curriculum elements is warranted, and some are easier to grasp than others. However, for more complex knowledge domains, such as history, or the scientific debate over the extinction of dinosaurs, the complexity of alternatives is beyond enumeration. And it is the complexity of this branching that really provides a qualitative break between older forms of PI and CAI and newer ITS. Not only is the branching in ITS complex, it is algorithmic and not enumerated, pre-defined, or hand-crafted. With this qualitative increase in complexity comes a flexibility of interaction and potential for communication that, better than anything else before, begins to qualify for the word intelligent. Another aspect of computer intelligence deals with the identification and remediation of errors (bugs) in a learner's knowledge structure or performance. The simple illustration with four hypothetical students shows the possible power of adding AI to instructional software that can recognize bugs or misconceptions via: (a) a bug catalog that specifically recognizes each mistake (e.g., Johnson & Soloway, 1984), (b) a set of mal-rules that define the kinds of mistakes possible with this set of problems (e.g., Sleeman, 1987), or (c) a set of production rules that specifically anticipate all alternative problem solutions and can respond to each one (e.g., Anderson, 1993; VanLehn, 1990). Each of these will be discussed in more detail in the section of this chapter outlining the 20+ year history of ITS. First, we need to operationalize some terms. |
|
|
|
|
AECT 877.677.AECT
(toll-free) |
|